写在前面
因为自己在学习使用flex&bison编写编译器时,困难很大,网上的资料很老很陈旧,很多示例代码都无法运行。幸而自己最终找到一份07年的博客,所以想对其整理一下。一来加深自己的理解,为学弟学妹提供一份参考资料,二来也能防止原博客丢失。
flex是lex的加强版,同样bison也是yacc的加强版,lex和yacc的语法适用于flex和bison,之后的博客内容将不区分flex和lex,bison和yacc。
本文所有的代码都在kali2019运行测试过,没有linux基础的读者可以安装Ubuntu系列linux,推荐ubuntu16和ubuntu18。
lex理论
Lex使用正则表达式从输入代码中扫描和匹配字符串。每一个字符串会对应一个动作。通常动作返回一个标记给后面的剖析器使用,代表被匹配的字符串。每一个正则表达式代表一个有限状态自动机(FSA)。我们可以用状态和状态间的转换来代表一个(FSA)。其中包括一个开始状态以及一个或多个结束状态或接受状态。
以文章一中的第一个例子来说明:
example1.l
1 | %{ |
这里使用一个相对简单的输入文件file.txt:
1 | i=1.344+39; |
我们假定,
Lex 系统创建一动态列表:内容+规则+状态
Lex 状态:1 接受 2 结束
接受表示该元素可以做为模式匹配
结束表示该元素已完成模式匹配
读入“i”:
[查找元素]查找相邻且状态为1的元素,无元素, [匹配规则]D, [新增列表<元素1>并置数据](存在则覆盖)状态为1,规则为D,内容为"i"。 [操作顺序符] 1
读入“=”:
[查找元素]查找相邻且状态为1的元素,“i=”寻找匹配规则,无规则 [置上一元素]<元素1>状态为2 [匹配规则]F, [新增列表<元素2>并置数据](存在则覆盖)状态为1,规则为F,内容为"=" [操作顺序符] 2
读入“1”:
[查找元素]查找相邻且状态为1的元素,“=1”寻找匹配规则,无规则 [置上一元素]<元素2>状态为2 [匹配规则]B, [新增列表<元素3>并置数据](存在则覆盖)状态为1,规则为B,内容为"1" [操作顺序符] 3
读入“.” :
[查找元素]查找相邻且状态为1的元素,“1.”寻找匹配规则,无规则,但有潜在规则C [匹配规则]F, [新增列表<元素4>并置数据](存在则覆盖)状态为1,规则为F,内容为"." [置上一元素]<元素3>状态为1 [操作顺序符] 4
读入“3”:
[查找元素]查找相邻且状态为1的元素,“1.3”寻找匹配规则,有规则 [置起始元素]状态为1,规则为C,内容为"1.3" [操作顺序符] 3 组合元素的起始操作符
读入“4”:
[查找元素]查找相邻且状态为1的元素,“1.34”寻找匹配规则,有规则 [置起始元素]状态为1,规则为C,内容为"1.34" [操作顺序符] 3 组合元素的起始操作符
读入“4”:
[查找元素]查找相邻且状态为1的元素,“1.344”寻找匹配规则,有规则 [置起始元素]状态为1,规则为C,内容为"1.344" [操作顺序符] 3 组合元素的起始操作符
读入“+”:
[查找元素]查找相邻且状态为1的元素,“1.344+”寻找匹配规则,无规则 [匹配规则]E, [新增列表<元素4>并置数据](存在则覆盖)状态为1,规则为E,内容为"+" [置上一元素]<元素3>状态为2 [操作顺序符] 4…
最后解析结果为
| 内容 | 规则 | 状态 | |
|---|---|---|---|
| <元素1> | i | D | 2 |
| <元素2> | = | F | 2 |
| <元素3> | 1.344 | C | 2 |
| <元素4> | + | E | 2 |
| … |
上面列出的算法是仅属于个人的分析,是相对直观且便于理解的,也可以参照这个算法用C语言模拟出lex的效果。不过真正的Lex算法肯定是更为复杂的理论体系,这个没有接触过,有兴趣可以参看相关资料。
yacc的BNF文法
个人认为lex理论比较容易理解的,yacc要复杂一些。
我们先从yacc的文法说起。yacc文法采用BNF(Backus-Naur Form)的变量规则描述。BNF文法最初由John Backus和Peter Naur发明,并且用于描述Algol60语言。BNF能够用于表达上下文无关的语言。现代程序语言大多数结构能够用BNF来描述。
举个加减乘除的例子来说明:1+2/3+4*6-3
BNF文法表示如下:
1 | E = num 规约a 优先级0 |
这里像(E表达式)这样出现在左边的结构叫做非终结符(nonterminal)。像(num标识符)这样的结构叫终结符(terminal,读了后面内容就会发现,其实是由lex返回的标记),它们只出现在右边。
我们将”1+2/3+46-3”逐个字符移进堆栈,如下所示:
| | .1+2/3+46-3 | |
| – | – | – |
| 1 | 1.+2/3+46-3 | 移进 |
| 2 | E.+2/3+46-3 | 规约a |
| 3 | E+.2/3+46-3 | 移进 |
| 4 | E+2./3+46-3 | 移进 |
| 5 | E+E./3+46-3 | 规约a |
| 6 | E+E/.3+46-3 | 移进 |
| 7 | E+E/3.+46-3 | 移进 |
| 8 | E+E/E.+46-3 | 规约a |
| 9 | E+E/E+.46-3 | 移进 |
| 10 | E+E/E+4.6-3 | 移进 |
| 11 | E+E/E+E.6-3 | 规约a |
| 12 | E+E/E+E.6-3 | 移进 |
| 13 | E+E/E+E6.-3 | 移进 |
| 14 | E+E/E+EE.-3 | 规约a |
| 15 | E+E/E+EE-.3 | 移进 |
| 16 | E+E/E+EE-3. | 移进 |
| 17 | E+E/E+EE-E. | 规约a |
| 18 | E+E+EE-E. | 规约b |
| 19 | E+E+E-E. | 规约c |
| 20 | E+E-E. | 规约d |
| 21 | E-E. | 规约d |
| 22 | E. | 规约e |
我们在实际运算操作中是把一个表达式逐步简化成一个非终结符。称之为“自底向上”或者“移进归约”的分析法。
点左面的结构在堆栈中,而点右面的是剩余的输入信息。我们以把标记移入堆栈开始。当堆栈顶部和右式要求的记号匹配时,我们就用左式取代所匹配的标记。概念上,匹配右式的标记被弹出堆栈,而左式被压入堆栈。我们把所匹配的标记认为是一个句柄,而我们所做的就是把句柄向左式归约。这个过程一直持续到把所有输入都压入堆栈中,而最终堆栈中只剩下最初的非终结符。
在第1步中我们把1压入堆栈中。第2步对应规则a,把1转换成E。然后继续压入和归约,直到第5步。此时堆栈中剩下E+E,按照规则d,可以进行E=E+E的合并,然而输入信息并没有结束,这就产生了“移进-归约”冲突(shift-reduce conflict)。在yacc中产生这种冲突时,会继续移进。
在第17步,E+E/E,即可以采用E+E规则d,也可以采用E/E规则b,如果使用E=E+E规约,显然从算法角度是错误的,这就有了运算符的优先级概念。这种情况称为“归约-归约”冲突(reduce-reduce conflict)。此时yacc会采用第一条规则,即E=E/E。这个内容会在后面的实例做进一步深化。
利用lex和yacc模拟简单计算器
源代码:
calculate.l
1 | %{ |
calculate.y
1 | %{ |
编译运行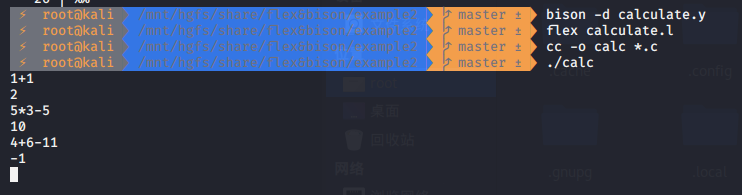
这里有两个文件calculate.y和calculate.l。calculate.y是yacc文件,bison -d lexya_a.y编译后会产生 calculate.tab.c calculate.tab.h。lex文件calculate.l中头声明已包括了calculate.tab.h。这两个文件是典型的互相协作的示例。
现在我们来分析下这个代码
(1)定义段和预定义标记部分
yacc文件定义和lex十分相似,分别以%{,}%,%%,%%分界。
1 | %{ |
这一段十分容易理解,只是头文件一些引用说明。成为“定义”段。
1 | %token INTEGER |
这一段可以看作预定义标记部分。%token INTEGER定义声明了一个标记。当我们编译后,它会在calculate.tab.c中生成一个剖析器,同时会在calculate.tab.h产生包含信息:# define INTEGER 257其中0-255的之间的标记值约定为字符值,是系统保留的后定义的token。calculate.tab.h其它部分是默认生成的,与token INTEGER无关。
1 |
|
lex文件需要包含这个头文件,并且使用其中对标记值的定义。为了获得标记,yacc会调用yylex。yylex的返回值类型是整型,可以用于返回标记。而在yylval变量中保存着与返回的标记相对应的值。
yacc在内部维护着两个堆栈,一个分析栈和一个内容栈。分析栈中保存着终结符和非终结符,并且记录了当前剖析状态。而内容栈是一个YYSTYPE类型的元素数组,对于分析栈中的每一个元素都保存着一个对应的值。例如,当yylex返回一个INTEGER标记时,把这个标记移入分析栈。同时,相应的yacc值将会被移入内容栈中。分析栈和内容栈的内容总是同步的,因此从栈中找到对应的标记值是很容易的。
比如lex文件中下面这一段:[0-9]+ { yylval = atoi(yytext); return INTEGER; }
这是将把整数的值保存在yylval中,同时向yacc返回标记INTEGER。即内容栈存在了整数的值,对应的分析栈就为INTEGER标记了。yylval类型由YYSTYPE决定,由于它的默认类型是整型,所以在这个例子中程序运行正常。
lex文件还有一段:[-+*/\n] return *yytext;
这里显然只是向yacc的分析栈返回运算符标记,系统保留的0-255此时便有了作用,内容栈为空。把“-”放在第一位是防止正则表达式发现类似a-z的歧义。
再看下面的:
1 | %left '+' '-' |
%left 表示左结合,%right 表示右结合。最后列出的定义拥有最高的优先权。因此乘法和除法拥有比加法和减法更高的优先权。+ - * / 所有这四个算术符都是左结合的。运用这个简单的技术,我们可以消除文法的歧义。
注:关于结合性,各运算符的结合性分为两种,即左结合性(自左至右)和右结合性(自右至左)。例如算术运算符的结合性是自左至右,即先左后右。如有表达式x-y+z则y应先与“-”号结合, 执行x-y运算,然后再执行+z的运算。这种自左至右的结合方向就称为“左结合性”。而自右至左的结合方向称为“右结合性”。 最典型的右结合性运算符是赋值运算符。如x=y=z,由于“=”的右结合性,应先执行y=z再执行x=(y=z)运算。
(2)规则部分
1 | program: |
这部分其实就是BNF文法,学了编译原理的同学应该能很快看懂。
这个规则乍看起来的确有点晕,关键一点就是要理解yacc的递归解析方式。program和expr是规则标记,但是作为一个整体描述表达式。先看expr,可以由单个INTEGER值组成,也可以有多个INTERGER和运算符组合组成。
以表达式“1+4/2*3-0”为例,1 4 2 3都是expr,就是expr+expr/expr*expr-expr说到底最后还是个expr。递归思想正好与之相反,逆推下去会发现expr这个规则标记能表示所有的数值运算表达式。
了解了expr后,再看program,首先program可以为空,也可以用单单的expr加下“\n”回车符组成,结合起来看program定义的就是多个表达式组成的文件内容。
粗略有了概念之后,再看lex如何执行相应的行为。以expr: expr '+' expr { $$ = $1 + $3; }为例:
在分析栈中我们其实用左式替代了右式。在本例中,我们弹出“ expr ‘+’ expr ”然后压入“expr”。我们通过弹出三个成员,压入一个成员来缩小堆栈。在我们的代码中可以看到用相对地址访问内容栈中的值。如$1,$2,这样都是yacc预定义可以直接使用的标记。“$1”代表右式中的第一个成员,“$2”代表第二个,后面的以此类推。“$$”表示缩小后的堆栈顶部。在上面的动作中,把对应两个表达式的值相加,弹出内容栈中的三个成员,然后把得到的和压入堆栈中。这样,保持分析栈和内容栈中的内容依然同步。
而
1 | program: |
说明每当一行表达式结束时,打印出第二个栈值,即expr的值,完成字符运算。
后记
如果到这里能完全理解所述内容,对于lex和yacc就有些感觉了。后面文章会做进一步的深入。