写在前面
看书、看博客永远是看别人替你总结的东西,想根本弄懂Java我觉得还是要看完Java的源码。jdk1.8是比较经典的一个Java版本,Oracle在该版本加入lambda表达式、新日期API和溢出hotspot永生代很多功能,因此选择该版本作为阅读版本。
为减少篇幅,并没有把所有代码全部粘贴至文中,但是会尽力介绍到每一个方法。
概要
我们从rt.jar包中最常用的数据结构类开始分析,rt全称runtime,是java的核心jar包。
ArrayList底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。它是线程不安全的,允许元素为null。
ArrayList位于java.util包下,先看一下它的关系图
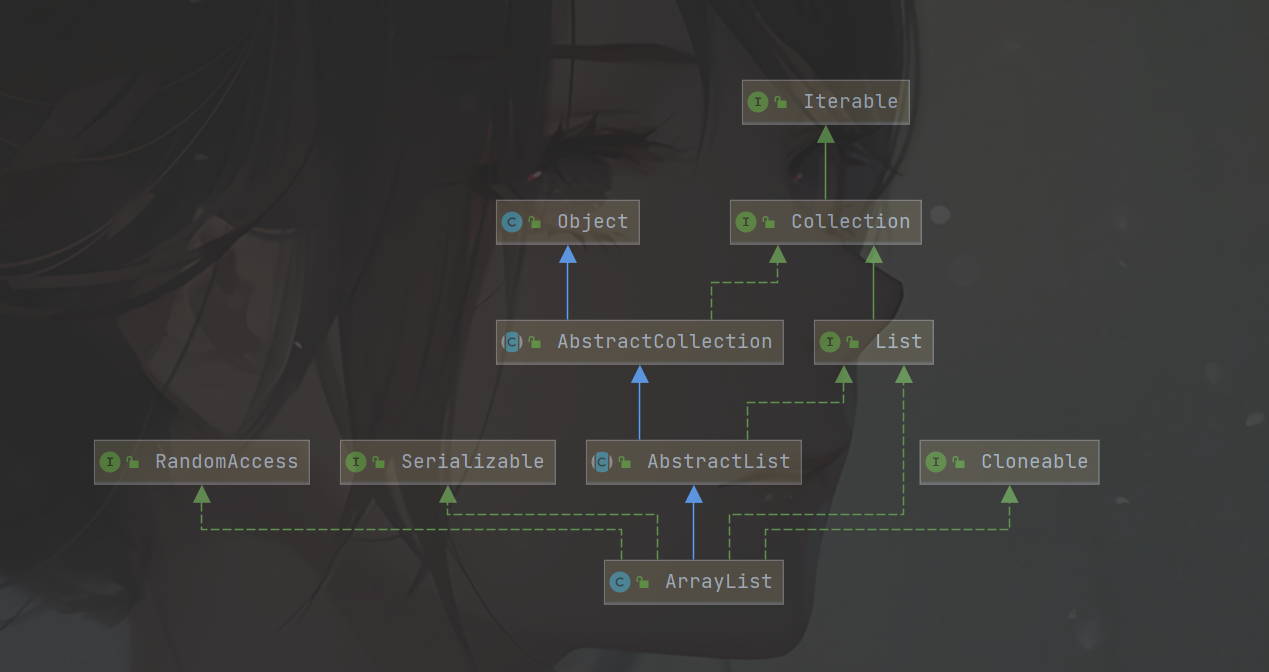
ArrayList继承自AbstractList类,并且实现了RandomAccess,Cloneable,Serializable 和 List接口,即支持随机访问,克隆,序列化。
如果深入查看,会发现RandomAccess,Cloneable,Serializable这三个都是空接口,没有指定任何方法,这样的接口叫标识接口,主要作用是为了标识,表明该类实现了哪些功能。这样做的好处是其他方法调用该类对象时,直接查看该类有实现某些接口来做些判断。
构造方法
1 |
|
ArrayList总共有三个构造函数,第一个参数给定初始容量,源码很好理解,当给定容量为0时,其elementData为被赋为空。DEFAULTCAPACITY_EMPTY_ELEMENTDATA和EMPTY_ELEMENTDATA没有啥本质上的区别,只是为了区分这两种空数组对应不同情况的初始化。
其他API
我们对其他api一个一个分析
trimToSize()
1 | //将list的容量变为当前大小,利用该操作可以最小化一个ArrayList的存储消耗 |
modCount是一个特殊的变量,继承自AbstractList,用来记录修改次数,监测迭代器迭代的时候是否发生修改。
ensureCapacity
1 | /** |
该函数主要是用于 防止一瞬间存储大量数据,导致不停扩容(之后的函数会提到)产生的时间消耗 , 通过该函数可以直接扩容到用户指定的容量。
ensureExplicitCapacity
1 | private void ensureExplicitCapacity(int minCapacity) { |
要求的精确容量只有不小于现有容量时,才会发生grow(扩容)。
grow
1 | /** |
1 | public static <T> T[] copyOf(T[] original, int newLength) { |
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右。如果newCapacity大于规定的最大size,会被通过hugeCapacity重新赋值。
再通过调用Arrays.copyof方法复制出新的数组给elementData。
hugeCapacity
1 | private static int hugeCapacity(int minCapacity) { |
如果minCapacity小于0,说明已经溢出,导致符号位置一,所以为负。
size
1 |
|
返回ArrayList大小。
isEmpty
1 |
|
判空函数
contains
1 | /** |
通过indexOf函数查找目标下标,下标为负即不存在。
indexOf
1 |
|
查找目标在ArrayList中第一次出现的位置。
lastIndexOf
1 | /** |
和indexOf正巧相反,返回目标在ArrayList最后一次出现的位置。
clone
1 |
|
克隆函数,可以发现ArrayList克隆并不去调用存储对象的克隆,也就是‘浅拷贝’。
toArray
1 |
|
返回elementData数组的拷贝,并可以把它强转成用户定义的类型,也因此加上@SuppressWarnings("unchecked")注解。
get
1 |
|
获取下标为index的数据,先检查边界(index为负会在elementData函数中报错),然后通过elementData返回值。
set
1 | public E set(int index, E element) { |
add
1 | /** |
首先确保ArrayList容量足够,然后进行赋值。
ensureCapabilityInternal
1 | private static int calculateCapacity(Object[] elementData, int minCapacity) { |
remove
1 | /** |
调用remove(int index)函数会将旧值返回。
由于是数组,所以删除完后会将之后的数组前移。
clear
1 | public void clear() { |
清空数组,是通过遍历而不是直接置换成空数组。
addAll
1 | public boolean addAll(Collection<? extends E> c) { |
ArrayList提供了两种addAll方法,一个指定下标,一个默认在队尾添加。指定下标会先检查边界。
两者都会先确定容量,对数组进行扩容,在进行赋值操作。
ps:rangeCheck和rangeCheckForAdd两个函数是不一样的,rangeCheck只判断了上界,下界交给了数组自身去判断,而用到rangeCheckForAdd的函数并不会用到数组自带的下标判断,所以需要判断下下界。
removeRange
1 | protected void removeRange(int fromIndex, int toIndex) { |
数组左移复制后,将之后的元素全部置空。
removeAll,retainAll
1 | public boolean removeAll(Collection<?> c) { |
retainAll是让elementData仅保存提供的collection里的元素,而removeAll正巧相反,删除提供的collection里的元素。
在batchRemove中通过一个boolean即区分开来(太巧妙了!)
为了加快处理速度,先定义了一个final的elementData数组(当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。这种和C语言中的宏替换有点像。变量被final修饰,会被当做编译器常量,所以在使用到该变量的地方会直接将变量替换为它的值。)
接着遍历elementData数组,通过判断collection中是否存在该元素而判断元素的存留。
由于c.contains可能会抛出异常,存在r!=size的情况,未处理到的元素默认保留在数组内。
如果正常处理结束,将超过size的元素置为空,等待gc回收内存。
writeObject,readObject
1 | private void writeObject(java.io.ObjectOutputStream s) |
这两个完成了ArrayList和ObjectOutputStream之间的相互转换,也就是让ArrayList有了序列化的功能。
在writeObject的过程通过CAS的方法,保证操作的原子性。
由于自己还没阅读序列化相关代码s.readInt()和SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);还不太懂其用处。
lambda函数
1 |
|
forEach、replaceAll和sort比较好理解,都是直接遍历数组,执行函数式接口的方法。removeIf其实也一样,只是逻辑比较漂亮,想分析一下。
先遍历数组,执行函数利用bitSet标记要清除的元素,然后再进行遍历数组,筛除需要删除的元素(发现没啥好解释的,大家看源码体会代码的艺术吧)。
结尾
剩下的源码也就是ArrayList的几个内部类了,我打算放在第二章来分析。